고정 헤더 영역
상세 컨텐츠
본문
DB에서 인덱스의 역할은 이름표 혹은 주소와 같은 역할을 합니다.
당연히 각 데이터가 주소를 가지고 있기 때문에 검색 기능에서 효율성이 높아집니다.
인덱스를 만드는 방법은 테이블의 특정 칼럼을 기준으로 만드는 것인데
데이터를 구분하는 ket와 테이블의 칼럼의 값으로 저장합니다.
아래의 그림이 제일 대표적인 예입니다.

Index가 있으면 왜 검색이 빨라지는지 예시를 들어보겠습니다.
서점에 있는 책에 대한 정보가 DB에 저장되어 있다고 가정하겠습니다.
해당 정보는
book = {
name : '자바스크립트',
category : '학습서',
author : '비굴이'
}
의 형태를 띄고 있다고 하면 DB에는

등의 형태로 저장될 것입니다.
새로운 데이터는 계속해서 쌓이게 되고 양은 방대해지게 될 것입니다.
이 때에 소설 카테고리만 확인하려고 한다면
전체 데이터를 다 읽어보고 category가 소설인 데이터만 가지고 올 것입니다.
이를 Full-scan이라고 하는데 매번 전체 데이터를 읽어야 하기 때문에
비효율적이며 시간도 오래 걸릴 것입니다.
이 때 인덱스를 만들게 된다면 아래와 같습니다.
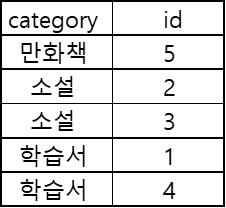
여기서 소설만을 확인하게 되면 id 값이 2,3이라는 것을 알게 되고
이 부분으로 기존 테이블에서 No값이 2,3만 찾으면 되기 때문에
테이블의 모든 데이터를 확인할 필요가 없어서 효율적이게 됩니다.
문제점
인덱스를 활용하게 되면 CRUD 중 Read에서는 굉장한 효율성을 얻을 수 있지만
C,U,D 부분에서는 효율성이 낮아지게 됩니다.
또 다른 테이블에서도 CUD가 진행되어야 하기 때문입니다.
때문에 인덱스를 추가하는 것이 효율적인지 상황에 맞게 적용하는 것이 좋습니다.
'CS 공부' 카테고리의 다른 글
| [CS공부] 제네릭 (Generic) : 타입스크립트(Typescript) (0) | 2023.03.31 |
|---|---|
| [CS공부] MSA (Micro-Service Architecture) 란? (0) | 2023.03.31 |
| [CS공부]REST API란? (0) | 2023.03.28 |
| [cs공부]객체 지향 프로그래밍 (OOP) (0) | 2023.03.27 |
| [자습시간] 멱등성(idempotent) HTTP 메서드의 성질 (0) | 2023.03.20 |




